
v0.2.1 · Now on PyPI
RagBucket
Portable executable .rag artifacts for Python. Package your entire RAG pipeline into a single file. Build once. Load anywhere.
$
uv add ragbucket
scroll
Portable executable .rag artifacts for Python. Package your entire RAG pipeline into a single file. Build once. Load anywhere.
ML models travel as single files — .pt .onnx .gguf .h5 — saved, shared, deployed anywhere.
RAG pipelines don't. They're a web of infrastructure, scattered config, and provider lock-in.
A compressed, self-contained archive that packages your entire retrieval system. Vectors, chunks, and config — everything in one file. The only external dependency at inference time is an LLM API key.
Two completely decoupled phases: build-time artifact generation and runtime retrieval + generation. The artifact is the bridge.
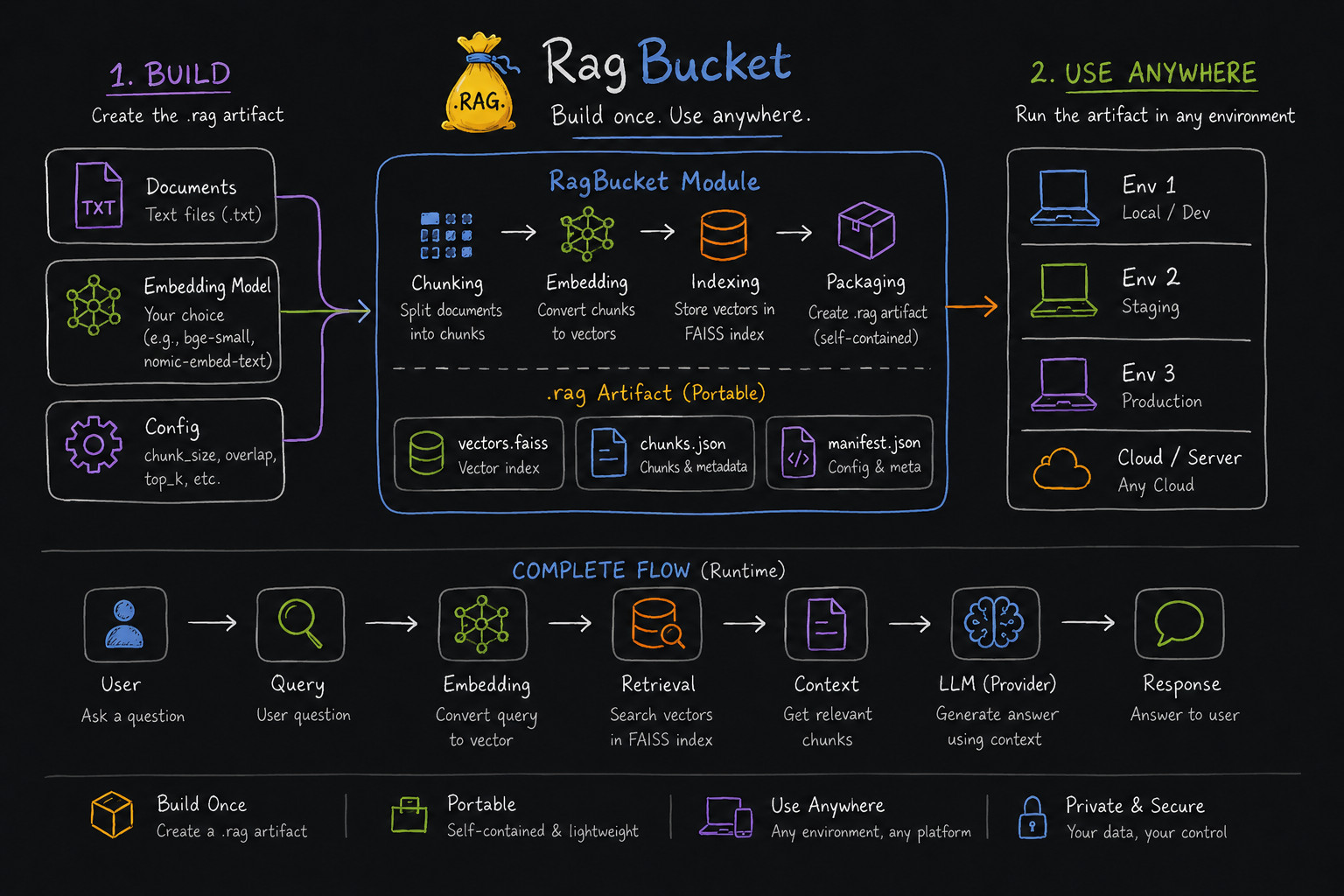
Build your artifact from documents. Load and query it anywhere — with any LLM provider.
from ragbucket import RagBuilder, RagConfig # Configure the pipeline config = RagConfig( embedding_model="BAAI/bge-small-en-v1.5", chunk_size=512, chunk_overlap=50, top_k=3, ) # Build the .rag artifact builder = RagBuilder(config=config) builder.build( doc_path="docs/", # folder of .txt files op_path="demo.rag", # output artifact ) # ✓ demo.rag created # Contains: vectors.faiss + chunks.json + manifest.json
from ragbucket import RagRuntime import os from dotenv import load_dotenv load_dotenv() # Load the artifact — works from any environment rag = RagRuntime( rag_path="demo.rag", provider="groq", # groq | openai | gemini | anthropic api_key=os.getenv("GROQ_API_KEY"), model="llama-3.1-8b-instant", system_prompt="You are a helpful assistant.", ) # Ask anything response = rag.ask("What are Anik's AI/ML skills?") print(response)
from ragbucket import RagConfig # All fields are optional — defaults are sensible config = RagConfig( # Any Sentence Transformers compatible model embedding_model="BAAI/bge-small-en-v1.5", # Chunking chunk_size=512, chunk_overlap=50, # How many chunks to retrieve per query top_k=3, ) # Supported embedding models: # "BAAI/bge-small-en-v1.5" fast, great for English # "BAAI/bge-base-en-v1.5" balanced quality/speed # "sentence-transformers/all-MiniLM-L6-v2" # "sentence-transformers/all-mpnet-base-v2"
Plug in any LLM provider, any embedding model, any vector store. RagBucket handles the wiring.